OVE6D: Object Viewpoint Encoding
for Depth-based 6D Object Pose Estimation
- Dingding Cai Tampere University
- Janne Heikkilä University of Oulu
- Esa Rahtu Tampere University
Abstract
This paper proposes a universal framework, called OVE6D, for model-based 6D object pose estimation from a single depth image and a target object mask. Our model is trained using purely synthetic data rendered from ShapeNet, and, unlike most of the existing methods, it generalizes well on new real-world objects without any fine-tuning. We achieve this by decomposing the 6D pose into viewpoint, in-plane rotation around the camera optical axis and translation, and introducing novel lightweight modules for estimating each component in a cascaded manner. The resulting network contains less than 4M parameters while demonstrating excellent performance on the challenging T-LESS and Occluded LINEMOD datasets without any dataset-specific training. We show that OVE6D outperforms some contemporary deep learning-based pose estimation methods specifically trained for individual objects or datasets with real-world training data.
Object-Agnostic Training for Unseen Objects 6D Pose Estimation
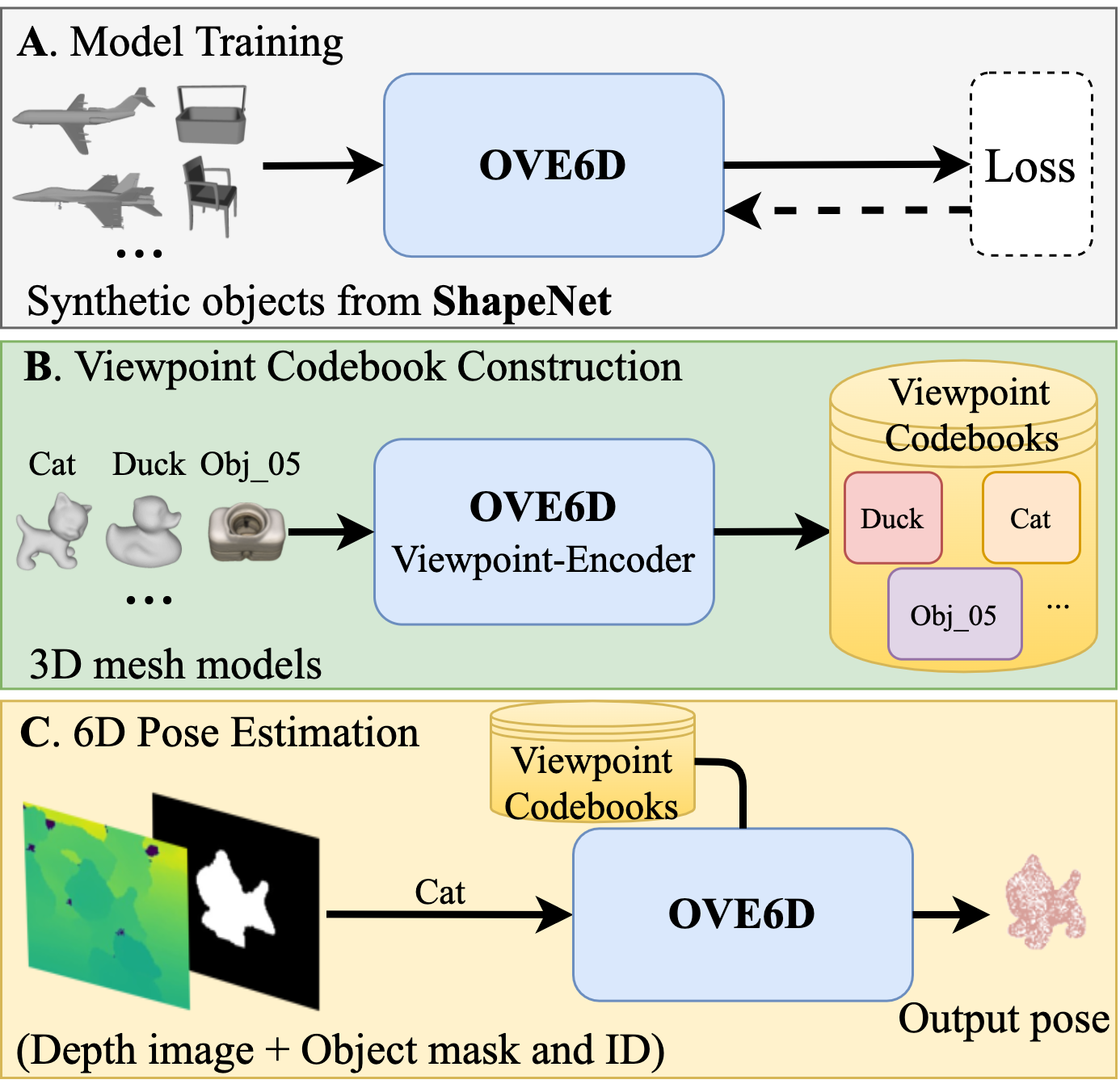
A) We propose a single universal pose estimation model (OVE6D) that is trained using more than 19,000 synthetic objects from ShapeNet. B) The pre-trained model is applied to encode the 3D mesh model of the target object (unseen during the training phase) into a viewpoint codebook. C) At the inference time, OVE6D takes a depth image, an object segmentation mask, and an object ID as an input, and estimates the 6D pose of the target object using the corresponding viewpoint codebook. New object can be added by simply encoding the corresponding 3D mesh model and including it into the codebook database (B).
Object Viewpoint Sampling and Latent Embedding Visualization
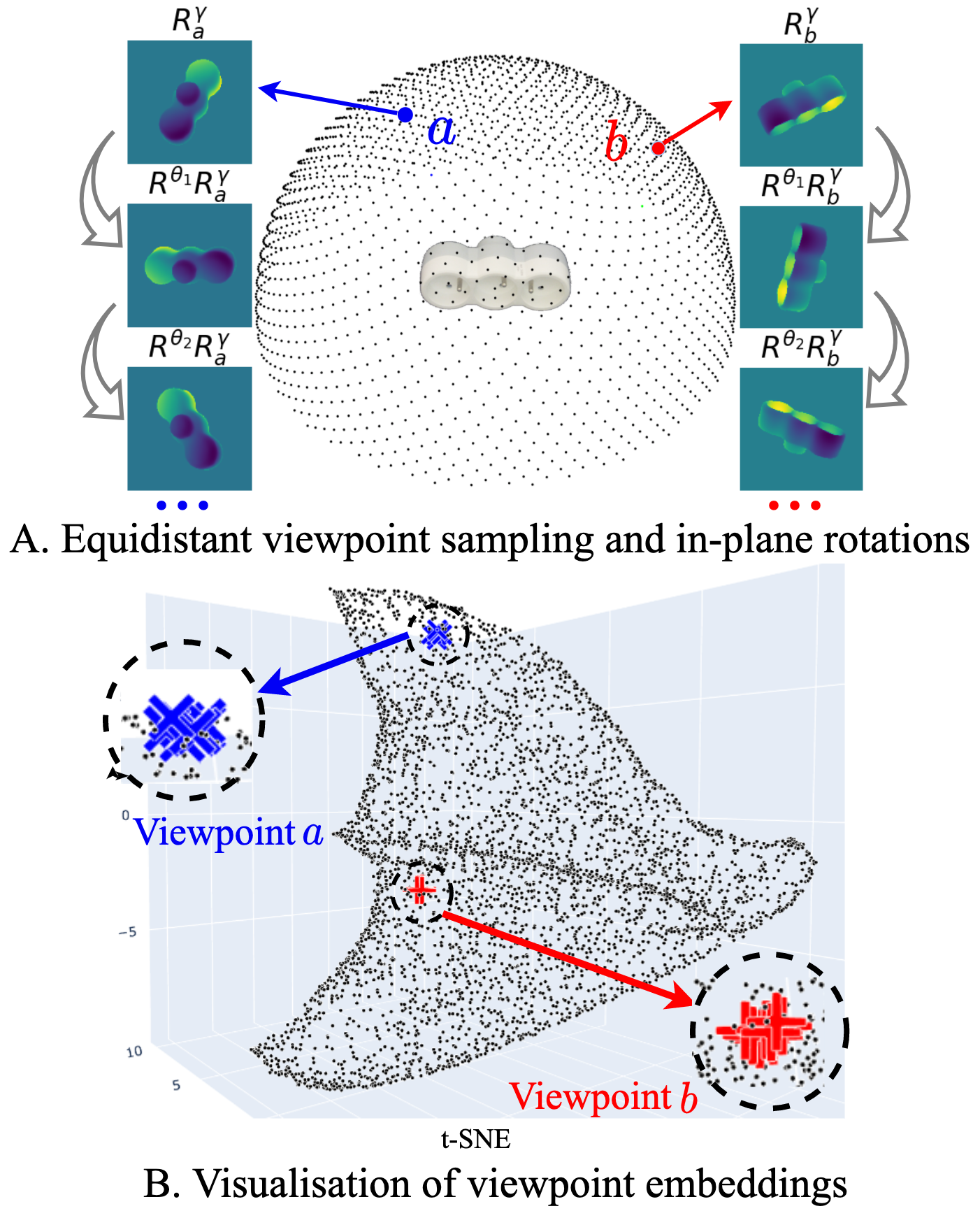
A) 4,000 viewpoints uniformly sampled from a sphere centered on the object (only the upper hemisphere is shown). The in-plane rotations Rθi around the camera optical axis are illustrated by synthesizing three examples at viewpoints a (Raγ) and b (Rbγ). B) The illustration of the proposed viewpoint embeddings using t-SNE [47], where the blue (’x’) and red (’+’) points correspond to the embeddings from 10 in-plane rotated views at the viewpoints a and b, respectively, and the black points represent the remaining viewpoints. It can be observed that the embeddings are relatively invariant to the in-plane rotations while varying with respect to the camera viewpoint.
Object Viewpoint Codebook Construction
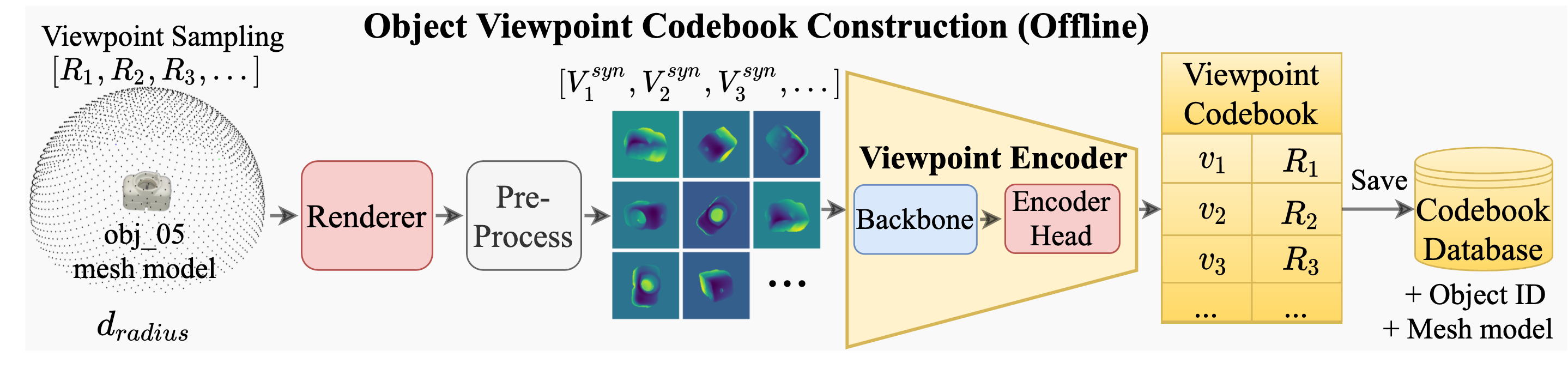
The viewpoints are sampled from a sphere centered on the object mesh model with a radius proportional to the object diameter. The viewpoint representations are extracted from the rendered depth images by the viewpoint encoder.
Inference Pipeline of OVE6D
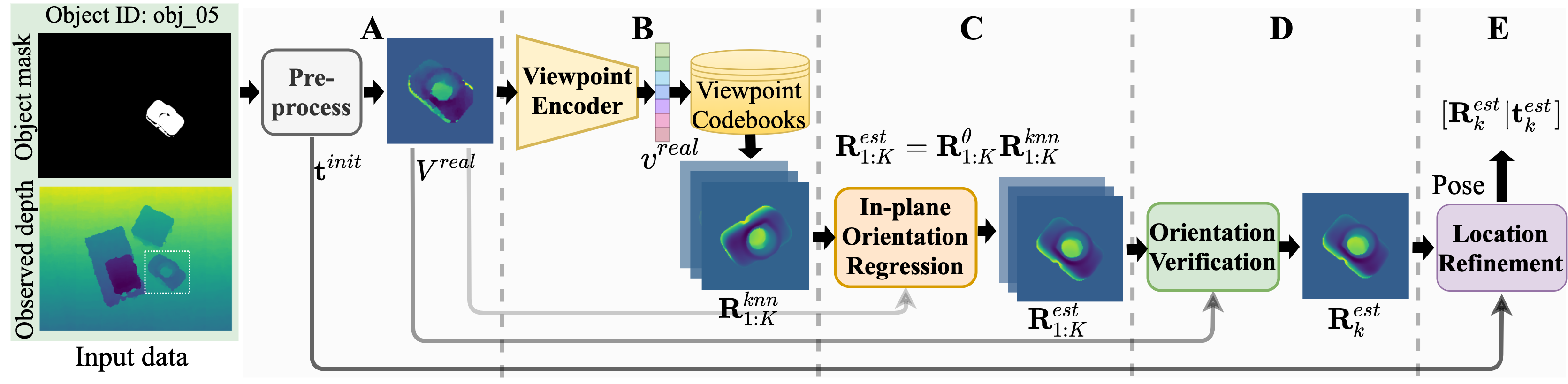
The entire system operates in a cascaded manner. First, the raw depth image is pre-processed to 128 × 128 input (A). Second, the object orientation is obtained by performing the viewpoint retrieval (B), in-plane orientation regression (C), and orientation verification (D). Finally, the object location is refined (E) using the obtained orientation and the initial location (A).
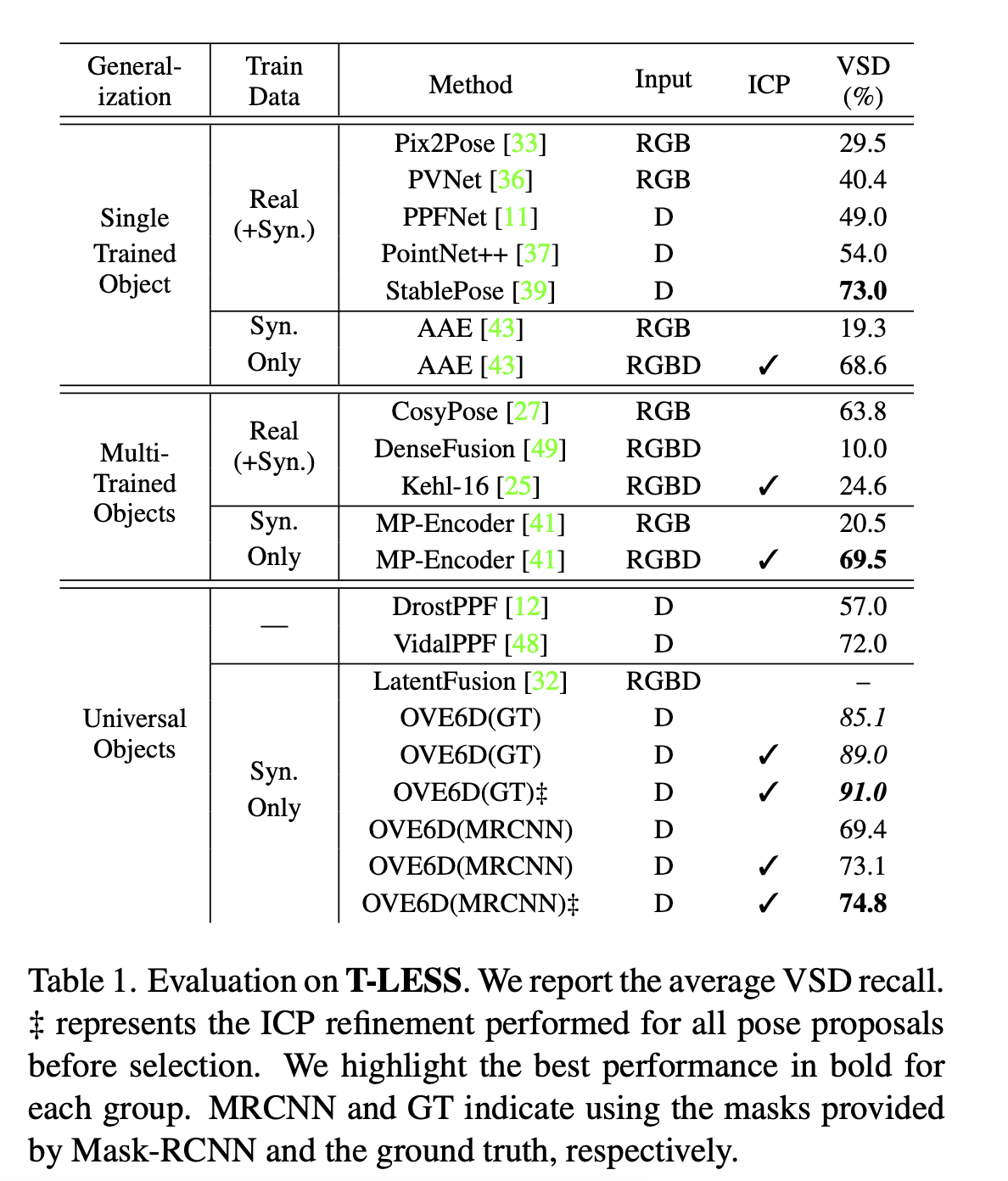
Evaluation Result on TLESS Dataset
Conclusion
In this work, we proposed a model (OVE6D) for inferring the object 6D pose in a cascaded fashion. The model was trained using a large body of synthetic 3D objects and assessed using three challenging real-world benchmark datasets. The results demonstrate that the model generalizes well to unseen objects without needing any parameter optimization, which significantly simplifies the addition of novel objects and enables use cases with thousands of objects. The main limitations of this approach include the requirements for the object 3D mesh model and instance segmentation mask, which may not always be easy to obtain.